Have you ever wanted to train your own Large Language Model (LLM) but felt overwhelmed by the setup process? Let's explore how Daytona's GPU-enabled infrastructure makes it surprisingly straightforward to experiment with training and fine-tuning existing models.
Many developers have played with various LLM models through APIs, but training custom models often seems daunting. The challenges of setting up local GPU environments, managing dependencies, and optimizing training parameters can be overwhelming. This is where cloud-based development environments like Codeanywhere, powered by Daytona, become invaluable.
This guide builds upon Andrej Karpathy's nanoGPT, a minimalist implementation designed to make GPT training accessible while maintaining high performance. As Karpathy describes it, nanoGPT prioritizes "teeth over education" - focusing on practical training rather than theoretical concepts.
TL;DR
Train your own GPT model without expensive hardware investment
Access enterprise-grade GPU power instantly through the cloud workspace
Monitor and visualize training progress in real-time
Fine-tune existing GPT-2 models for custom applications
Generate AI text completions using your trained model
Why Train Your Own GPT?
While using pre-trained GPT models is convenient, training your own model offers valuable insights into how language models learn, the effects of different hyperparameters, the relationship between training data and model behavior, and the practical considerations of computational resources and optimization.
Getting Started with Codeanywhere GPU Workspaces
Daytona removes the typical friction of GPU setup by providing infrastructure with instant access to GPUs. In this case, we partnered with Codeanywhere to provide NVIDIA T4 GPUs and are working with them to expand their offering depending on the user's needs.
First, visit codeanywhere.com and create a new account. Once logged in:
Click "Create" new workspace
Enter GitHub repository URL: https://github.com/karpathy/nanoGPT
Select workspace class (Premium GPU with NVIDIA T4 GPU, 16GB VRAM)
Click Continue to create the workspace
Performance Monitoring with Weights & Biases
Weights & Biases (W&B) provides real-time visualization of training metrics in this demo. The platform tracks loss values, GPU utilization, and model performance through a simple Python integration. During training, you can observe the learning progress through interactive dashboards, making it easier to identify potential issues and optimize parameters.
1wandb_log = True2wandb_project = 'shakespeare'3wandb_run_name = 'ft-' + str(time.time())
Training and Fine-Tuning an LLM in the Cloud Workspace
The nanoGPT implementation by Karpathy is remarkably efficient - achieving GPT-2 (124M) reproduction on OpenWebText in about 4 days on a single 8XA100 40GB node. The entire implementation is contained in just ~300 lines of training loop code and ~300 lines of model definition, making it ideal for experimentation and learning.
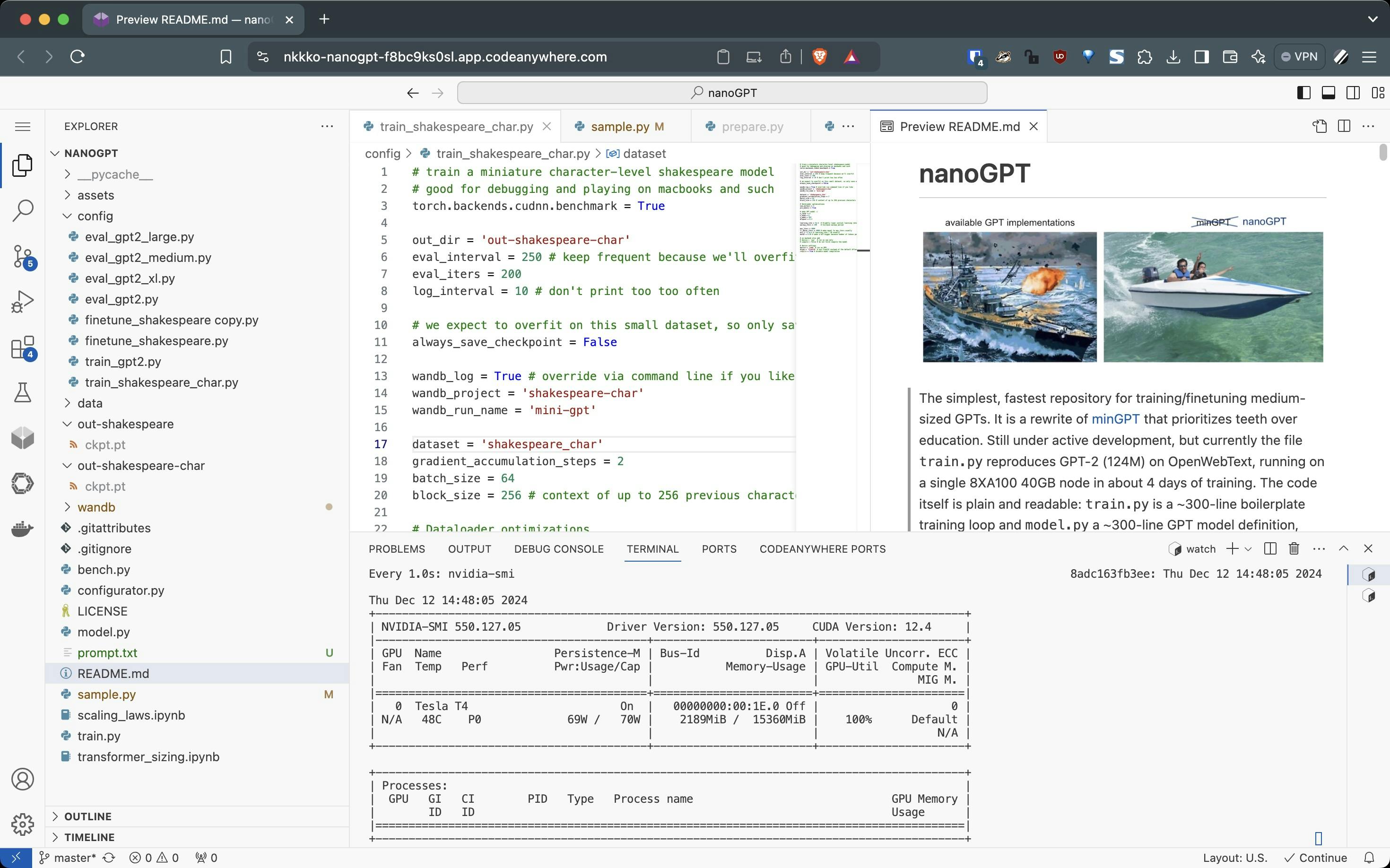
Training nanoGPT from Scratch
For this demo, several small changes were made to the original nanoGPT configuration:
Turned on Weights & Biases integration for monitoring
Switched to float16 precision for T4 GPU compatibility
Compiling the model and reducing the max iterations
1# Optimized training configuration2torch.backends.cudnn.benchmark = True3dtype = 'float16' # Using float16 for faster training4device = 'cuda'5compile = True
Now, you can start the training with:
1python train.py config/train_shakespeare_char.py
Testing Your Model
After training, test your model by creating a prompt.txt file with your desired input, running the inference script, and reviewing the generated output. To sample from the best model, use the sampling script and specify this directory.
1python sample.py --out_dir=out-shakespeare-char
Fine-tuning GPT-2
Following Karpathy's approach, we can fine-tune pretrained GPT-2 models (up to 1.3B parameters) on custom datasets. The nanoGPT implementation makes this process straightforward while maintaining the ability to achieve competitive performance.
Finetuning is essentially training with two key differences: starting from a pretrained model and using a lower learning rate. This process is fast, and finetuning can take just minutes on a single GPU.
For this demo, several small changes were made to the original nanoGPT configuration:
Start with pre-trained GPT-2 (124M parameters)
Reduced training iterations to 20 for quick results
Enabled gradient checkpointing to optimize memory usage
Configured smaller batch size and gradient accumulation steps
1# Modified configuration for fine-tuning2init_from = 'gpt2' # Start with pre-trained GPT-2 (124M parameters)3learning_rate = 3e-5 # Conservative learning rate4gradient_accumulation_steps = 16 # Effective batch size of 165max_iters = 20 # Quick fine-tuning pass
Now, you can start the fine-tuning with:
1python train.py config/finetune_shakespeare.py
Testing Your Fine-Tuned GPT-2
After fine-tuning is completed, you can then run the code:
1python sample.py --out_dir=out-shakespeare
This produces more coherent results much faster, demonstrating the power of transfer learning. The model maintains GPT-2's general language understanding while adapting to our specific training data.
The Power of Accessible GPUs
Daytona's GPU workspaces democratize AI experimentation by eliminating traditional barriers:
No complex driver installation
No fighting with Python and CUDA versions
Pre-configured deep learning environments
Simple subscription based pricing
This allows developers to focus on model architecture and training strategy rather than infrastructure management.
Start LLM Training Today
Training your own Large Language Model (LLM) has become increasingly accessible, thanks to cloud-based workspaces with GPU capabilities, such as Codeanywhere.
For more detailed understanding of GPT architecture and training, Karpathy's "Zero to Hero" series provides excellent background, particularly his dedicated GPT video tutorial. The nanoGPT repository continues to be actively developed with ongoing optimizations and improvements.
The power of GPU workspaces provided by Codeanywhere, powered by Daytona infrastructure, makes it possible to experiment with language models without the complexity of setting up your environments.