Large language models (LLMs) are advancing beyond raw parameter scaling, adopting architectures like a mixture of experts and specialized reasoning capabilities.
While these state-of-the-art (SOTA) models solve complex problems—debugging code, resolving dependency conflicts, or tackling advanced math—they introduce a critical UX challenge: latency.
Users expect instant responses, and even slight delays can feel disruptive. Here's how the industry can address this tension.
The Power and Trade-offs of Reasoning Models
Response time standards in computing have remained remarkably consistent over the past decades. Jakob Nielsen's seminal work established three important time limits that continue to influence user interface design:
0.1 second: Perceived as an instantaneous reaction
1.0 second: Limit for uninterrupted thought flow
10 seconds: Threshold for maintaining user attention
Reasoning models excel at multi-step problem-solving, generating intermediate "thought" processes to reach accurate answers. For example:
A coding error involving nested Pydantic validations might stump standard LLMs, but reasoning models can diagnose and resolve it systematically.
Math or logic puzzles require breaking down steps (e.g., "Calculate train distance: speed × time"), and reasoning models formalize this process.
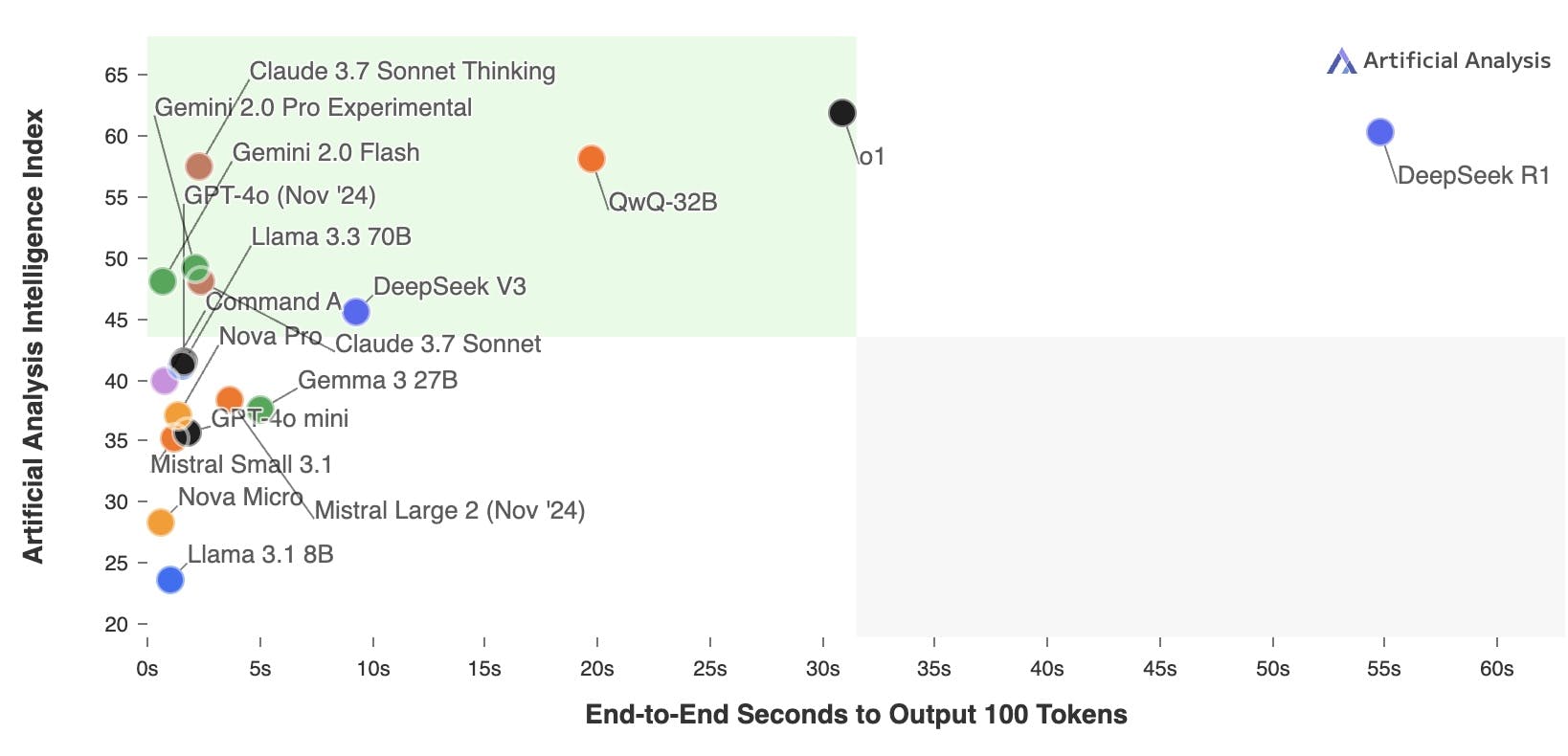
However, these models inherently take longer to generate responses. Users tolerate delays for hard problems (e.g., after hours of failed debugging) but expect near-instant replies for simpler tasks.
UX Solutions: Smart Routing and Tool Integration
To balance quality and speed, two strategies stand out:
Dynamic Model Routing
Simple tasks (factual QA, basic syntax fixes): Route to faster or lightweight models (e.g., Mistral 7B, GPT-4o).
Complex tasks (debugging, proofs): Use specialized reasoning models (e.g., o1, o3, DeepSeek-R1, Claude 3.7 Sonnet, etc).
Example: A coding assistant could auto-detect query complexity by directing "Fix Python indentation" to a speed-optimized model, while "Explain race condition in async code" triggers a reasoning model.
On-Demand Tool Execution
Tools like Daytona SDK enable models to offload computational work:
Spin up ephemeral environments to run code, test solutions, or install dependencies without blocking user interaction.
Agents can build/use tools in real-time (e.g., execute a script to validate a fix while the user continues working).
Result: The model "thinks" in the background, delivering answers when ready, while the UI remains responsive.
Why This Matters
Latency isn't just a technical problem—it's a perception problem. Users associate delays with incompetence, even if the output is superior. By combining:
Intelligent routing (right model for the task),
Asynchronous tools (let models work "offstage"),
Progressive responses (e.g., "Hold on, solving this…"),
Developers can leverage SOTA reasoning models without sacrificing UX. The future lies in hybrid systems where speed and depth coexist, guided by context-aware decision-making.
The Path Forward
Providers like OpenAI and Anthropic already experimented with tiered models and inference optimizations. For developers:
Use APIs with built-in routing (e.g., OpenAI's priority tiers).
Integrate tools like Daytona to handle compute-heavy steps.
Measure latency tolerance per use case—optimize where it matters.
Reasoning models are transformative, but their adoption hinges on seamless integration. The goal isn't just "smarter" AI—it's AI that feels effortless to use.